DETR系列总结
DETR (2020 Facebook AI)
在训练的阶段,利用和GT的二分图匹配,使得最终模型不需要使用NMS,同时因 为有learnable query,也不需要显式的anchor生成步骤。
需要注意的点:
- 预测的bbox和GT匹配时,既考虑了bbox的loss,也考虑了类别的loss;但是匹配用的Loss和监督Loss不完全一致;
- decoder中添加了辅助loss,具体来说,decoder的每一层都会进行预测、和gt匹配、计算loss的过程,其中预测头FFN是共享的。
DETR最大的问题是训练收敛速度太慢,后面一系列论文通过各种方式改进这个问题。
Deformable DETR(2021 SenseTime)
原始的DETR有以下问题:
- 没有利用多尺度的FPN图像特征
- 由于每个query需要attention所有的patch特征,收敛速度和特征分辨率都受到了限制
本文的改进方法受到Deformable Conv的启发,每个query只与固定数量的稀疏的图像特征进行交互,具体做法:
- 每个query对应一个content feature和一个reference point (2d),其中content feature是用随机初始化的,reference point是由content feature通过linear projection+sigmoid得到;
- 通过linear proj得到N个offset坐标,每个坐标的attention weight也是通过linear proj + softmax得到;
- ref point加上offset坐标,在特征空间做双线性插值,得到keys’ set
需要注意,deformable attention中并没所有使用key * query,而是直接用query+线性层得到attention矩阵。
decoder中,每一层会回归bbox的offset,更新ref point的位置输入到下一层。
另外还提出了Two-Stage Deformable DETR,强调query的分布应该是和图像相关的:
在第一阶段,Encoder输出的FPN中的每个pixel都作为query直接预测一个bbox,取topk的bbox和对应的content feature,作为后续decoder的query。训练的时候应该还是一起训练的,第一阶段也会和gt做二分图匹配。
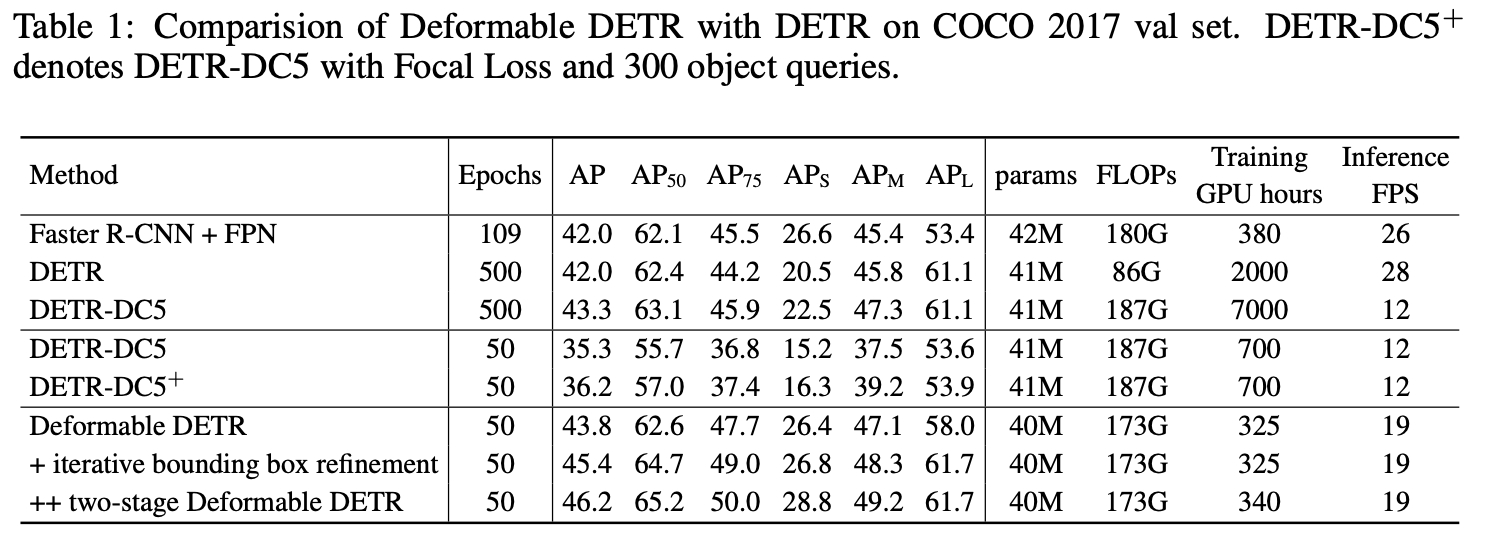
在COCO数据集上,原始DETR需要500个epoch,deformable DETR只需要50个epoch。
Conditional DETR(2021 USTC)
出发点也是为了解决DETR训练收敛太慢的问题,本文观察到DETR训练了50个epoch后,spatial attention(就是position embeding之间的attention)还是不够好,训练500以后才会比较好,并且最后预测时,即使去掉Postion embeding对最终的指标影响也不大,说明模型没有很好的利用空间信息。
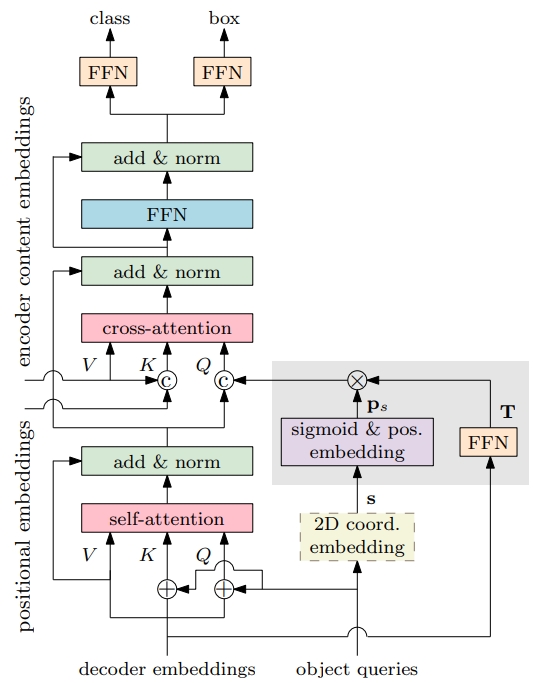
提出了Conditional attention:
- 每个query分为两个部分,一个是content query, 包括语义、尺寸,另一个是object query, 可以理解为position embeding,包含bbox中心点信息;
- 计算attention时,content query和图像特征做atttn,object query和图像的position embeding单独做attn,两部分加起来作为最终的attention matrix;
- object query的计算过程是同时融合了上一个decoder的content query和object query,这样objection query中就包含了四个边界的位置信息。
根据COCO实验结果来看,Conditional DETR只需要50个epoch就可以接近收敛,原始DETR需要500个epoch。
Anchor DETR(2022 megvii)
把原始DETR的query换成了显式的postion anchor,包含两种初始化策略: a. 在图像空间均匀分布 b. 在图像空间随机撒点
直接用这些position anchor进行编码,用来当作object query,另外,定义了3个pattern query附加在原来的position query上,使得同一个位置可以有多个检测结果;
简化cross attention的计算量,把图像空间的attention拆分为横向和纵向,减少计算量。
最终效果也是提升了收敛速度,只需要50个epoch 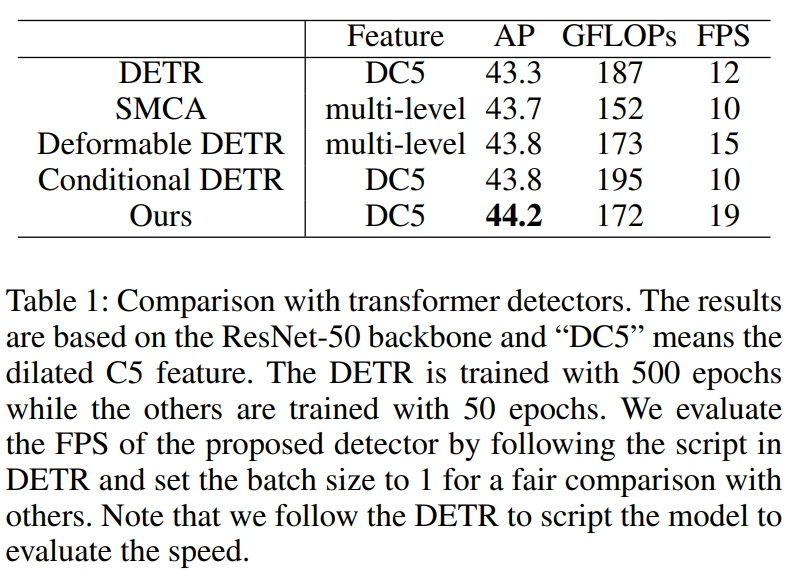
DAB-DETR (2022 Tsinghua)
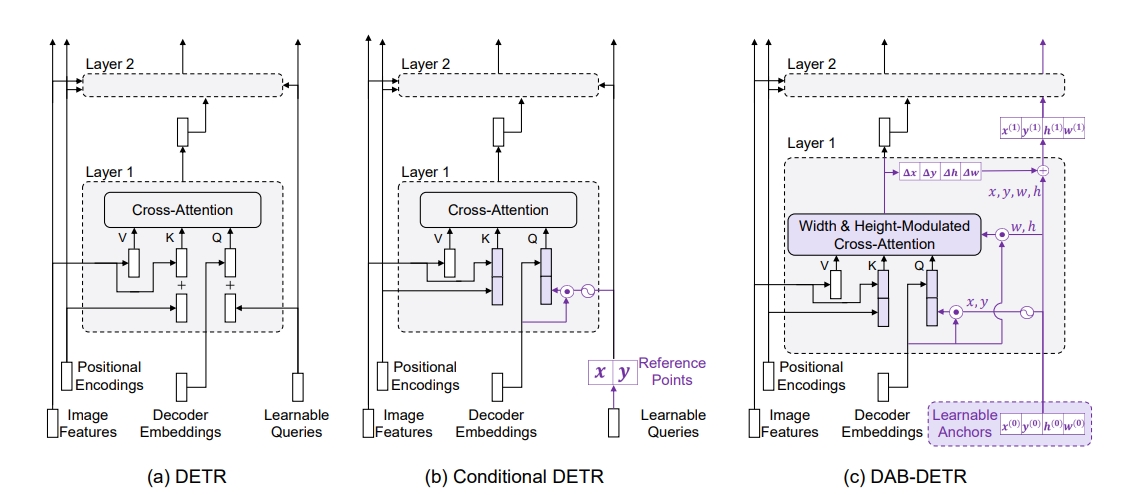
DAB:Dynamic anchor boxes
对DETR训练收敛慢的问题做了一些分析:首先可以确定的是,导致DETR收敛慢的原因是cross attention,所以有两种猜想:
- query的embeding特征太难学了;
- query的position encoding的方式和image特征不一致。
针对第一个问题,作者直接用训练好的DETR query特征,fix住开始训练,但是结果也是收敛很慢,说明不是query特征不好学的问题;所以问题还是出在postion信息上面。
核心思想是在condition detr的基础上,进一步考虑bbox尺寸对postion attention的影响,object query中除了中心点也把尺寸给加上了: 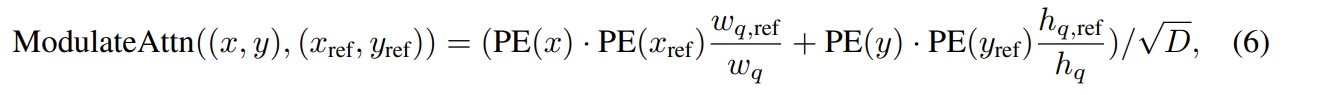
应该算是condition detr的改进,相同模型结构下提升1~2%的mAP。
DN—DETR(2022 HKUST)
这篇文章指出DETR收敛慢还有一个原因是二分图匹配导致的,特别是训练的初期,匹配的结果是非常不稳定的,同一个query在不同的epoch会匹配上不同的GT,导致模型无法有效的学习到如何正确的回归bbox的数值。因此,在训练过程中,提出了一个denoising的方法来辅助训练bbox的回归过程:
- 训练过程中,一部分query还是跟之前一样,与GT匈牙利匹配、计算loss,另一部分query由GT加噪声生成(同一个GT会生成多个query),不进行匹配,直接回归;
- 在DAB-DETR的基础上,把content query替换成了class embeding和一个indicator(表示query属于正常的还是通过gt添加的);
- 做query的self-attention时,添加了一个mask矩阵,防止不同类型的query交换信息
最终在DAB-DETR的基础上,又提升了接近2%的mAP。
DINO(2022 HKUST)
可以看成是结合了各种改进方式的一个方法,主要包括三个改进方面:
- Contrastive DeNoising Training
- 之前的DN-DETR里面,DN query全部都是正样本,导致背景类别没有很好的监督;
- 添加了一个更大的噪声参数,在GT的基础上生成偏差加大的bbox,作为样本来监督CND query,让模型学会把某一些query的类型判断为背景
- Mixed query selection
- 参考Two-Stage Deformable DETR的做法,使用encoder的feature直接预测bbox,然后选topk作为后续query;
- 不同的点在与,只使用bbox作为anchor信息,content feature是一个新的embeding,而不继承encoder的feautre
- Look Forward Twice
- bbox refine的时候,每一层的loss会影响两层的decoder参数
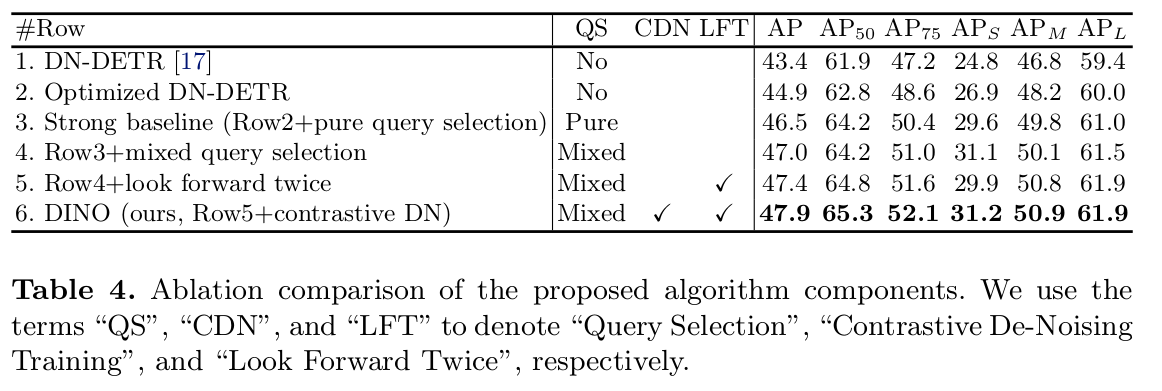
这一套组合改进下来,只需要24个epoch,就能达到SOTA的性能指标。从消融实验来看,每个改进带来0.5%左右的AP提升。
Group DETR(2023 Baidu)
在训练阶段,把query复制k-1份,形成k组query,每一组都和GT匹配、计算loss,每一组共享相同的decoder;预测阶段只用第一组query来进行。 相当于做了数据增强,同样一份数据会产生更多样的loss来监督模型收敛。最终可以带来1%左右的AP提升。
Co-DETR(2023 Sensetime)
DETRs with Collaborative Hybrid Assignments Training。
为了加强对encoder的训练,使用二阶段检测器的anchor generator做监督,添加了ATSS\Faster RCNN的anchor Head辅助训练。另外positive坐标和encoder的feature被编码成query用来回归GT。