Prediction方法总结
VectorNet(2020 waymo)

第一个提出通过矢量化的方式来编码地图和轨迹等context信息,通过PointNet提取每个地图要素的特征,然后通过self-attention的GNN来获得最终的地图编码。用了一个MLP作为decoder来预测轨迹。
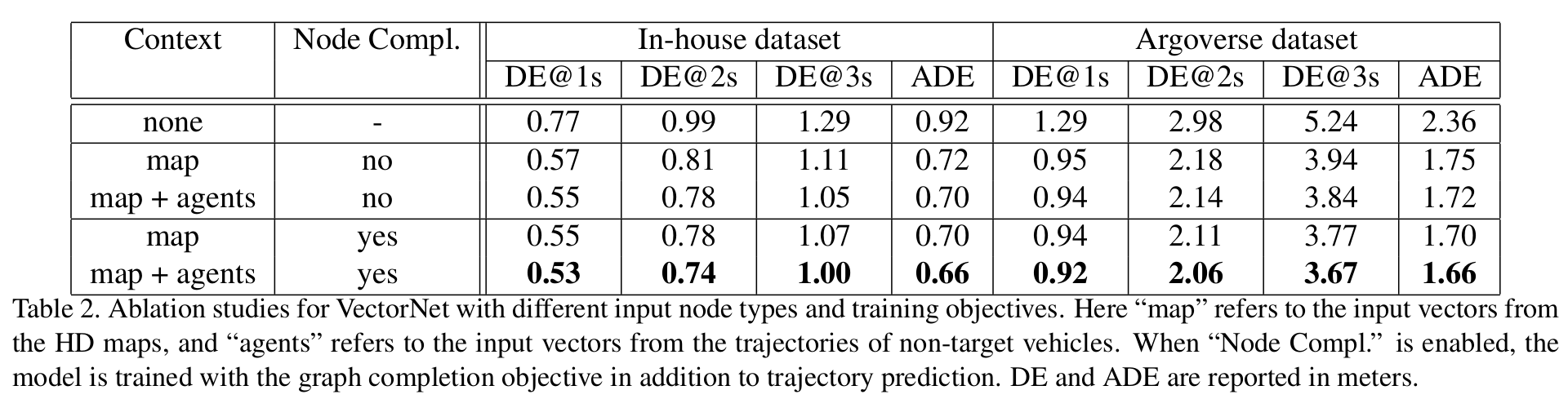
训练的时候随机将一些graph中的特征mask掉来使得模型更好的学习到不同轨迹和地图的交互关系,并且模型会预测mask掉的特征。
To encourage our global interaction graph to better capture interactions among different trajectories and map polylines, we introduce an auxiliary graph completion task. During training time, we randomly mask out the features for a subset of polyline nodes
上述这个操作在Ablation study中展示出会稳定提升轨迹预测的性能。
实现过中的问题
实现的时候会遇到一个问题:每个地图包含的polyline数量不同,每个polyline的点数不同,他车轨迹数量、点数也各不相同。这个问题导致模型无法同时infer一个batch的数据。
解决的办法:
- 先做padding,把一个batch内的所有数据补齐到同一个维度
- PointNet中的max pooling操作需要添加一个点维度的mask,给padding的点加-inf
- self-attention的softmax之前给padding要素对应的feature加-inf
该方法同样适用于其他使用vector map encoder的模型。
TNT(2020 waymo) && DenseTNT(2021 Tsinghua)
TNT

TNT(Target-driveN Trajectory Prediction)采用和VectorNet一致的context encoder,与vectorNet最大的不同是提出了一种多模态轨迹预测的范式。
轨迹预测与不同目标的意图有关,例如一辆路口前的车可能左转也可能右转,根据”左转”和”右转”的这两种意图会产生两种不同的轨迹预测结果。考虑到目标的意图是难以准确预测的,所以可以输出多种可能的预测结果来供下游使用。
在TNT中,会首先预测一个目标将要到达的位置,然后根据这个位置来预测中间的轨迹。这个目标位置的预测分为两个步骤:
- 在空间中生成一些候选位置
- 对每个候选位置,通过模型学习出一个offset与候选位置相加
上述过程类似与2D检测中的anchor和bbox回归,另外上述的offset实际上是假设为一个方差为1的高斯分布的均值。在上述第1步的anchor选取时,针对车辆和行人做了两种不同的选取方式:

TNT通过两层MLP预测M个轨迹,通过轨迹和GT的距离来对每条轨迹的得分进行监督。infer阶段采用了NMS,并输出分数最大的K条轨迹。
DenseTNT
与TNT最大的不同:
- 使用了heatmap来取代原来的稀疏anchor;
- 使用了一个优化算法来生成目标位置,避免NMS门限设置的问题
DenseTNT会先用一个分类模型对Lane进行打分,然后在挑选出的候选lane上生成稠密的anchor,再利用anchor作为query与lane计算attention,通过一个MLP之后softmax得到每个anchor的分数。所有anchor的分数就构成了heatmap。通过优化算法选取目标位置,蒙特卡洛法随机撒点,不断迭代挑选一个概率最大的结果。
轨迹生成部分和TNT一样。
MultiPath(2019 waymo) && MultiPath++(2021 waymo)
MultiPath++主要基于MultiPath做了以下改进:
- context encoder使用了的矢量化的方法代替了图像的CNN encoder
- 提出了一种高效地取代cross-attention的方法,取名multi-context gating(MCG)。简单说就是多层MLP+Pooling,好处是相比cross-attetion降低了计算复杂度;
- 对轨迹的不同建模方式进行了实现和对比,主要包括三种方式: a. 模型直接预测位置 b. 通过多项式建模轨迹 c. 预测和加速度角速,通过加速度角速度递推轨迹
- 提出了一种轨迹预测的ensembling方法:使用多个regression head分别训练,输出多条轨迹采样,通过EM来估计GMM的分布
- 借鉴了DETR中的方法,通过一组可学习的参数来生成轨迹的anchor,准确的说应该是query;query的数量和最终预测的轨迹数量相同
MultiPath++输出的N条轨迹也会通过一个分类网络来打分。
MultiPath++把最终输出的k条轨迹看做一个Gaussian Mixture Model(GMM),而多个regression head输出的轨迹看做从这个GMM中的多个采样样本,通过EM来估计出最终的GMM分布。

消融实验如上图,比较值得注意的点:
- 使用ensembling之后有稳定的性能提升,最佳的参数是5个head,每个head输出6条轨迹
- 使用学习的anchor有稳定的性能提升
- 模型直接预测原始的坐标的精度最高,但同时带来的问题是存在一些物理不合理的轨迹,例如转弯半径过小
Scene Transformer(2022 waymo)
主要的创新点:
- 在统一的坐标系下进行预测,而不是以每个预测目标作为坐标系中心。这样做的核心目的是让模型一次能输出M组所有目标的轨迹,这样可以保证这些轨迹互不冲突,而单独预测每辆车的M条轨迹失去了与其他预测结果的关联性;
- factorized attention: 把时间、agent维度分别做attention。对每个轨迹的时间序列单独做self-attension,然后对agents维度做self-attention,这两个步骤交替进行来获得时间和agent之间的关联;
- 通过对GT进行不同的mask方式,实现不同的任务

WayFromer(2022 waymo)
- 使用了两种transformer中的机制,self-att和cross-att
- 对比了三种scene encoder: late fusion、early fusion、hierarchical fusion
- 对比了两种attention方式:factorized attention和lattent query attention,两种都是为了提升计算效率;并且factorized attention中也尝试了不同的组合顺序

轨迹的预测方式与multipath++一样。
ablation study中,三种scene encoder的效果以及三种attention方式的效果如下图。sequential, interleaved两种facotrized方式效果差不多。整体上看,hierarchical fusion+latent query最优。



QCNet(2023 CityU)
以一种优雅的方式解决了scene-centric和agent-centric这两种方式的弊端,并且可以复用历史数据的特征,极大提升了计算效率。
核心的坐标表示和scene encode方法:
- agent encoder中使用的状态量都转换到当前时间所在的local坐标系,计算相对上一时刻的位移量(转换到了极坐标系,并且用了傅里叶特征)、速度、角度、时间等等;
- cross-attention的时候,为了区别两个要素的坐标系,计算key和value的时候concat两个要素的相对位置

因为每次cross-att只会用附近的context,但是有的prediction horizon很长,因此使用了循环query的方式来解决。